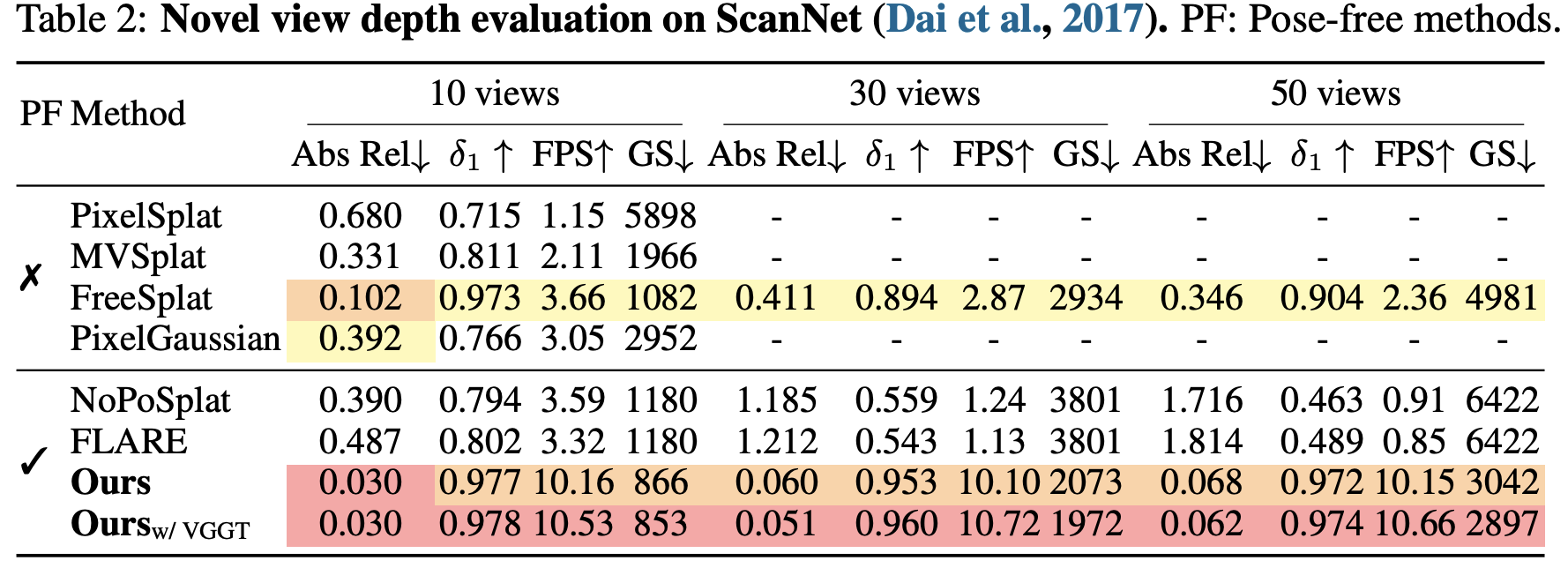
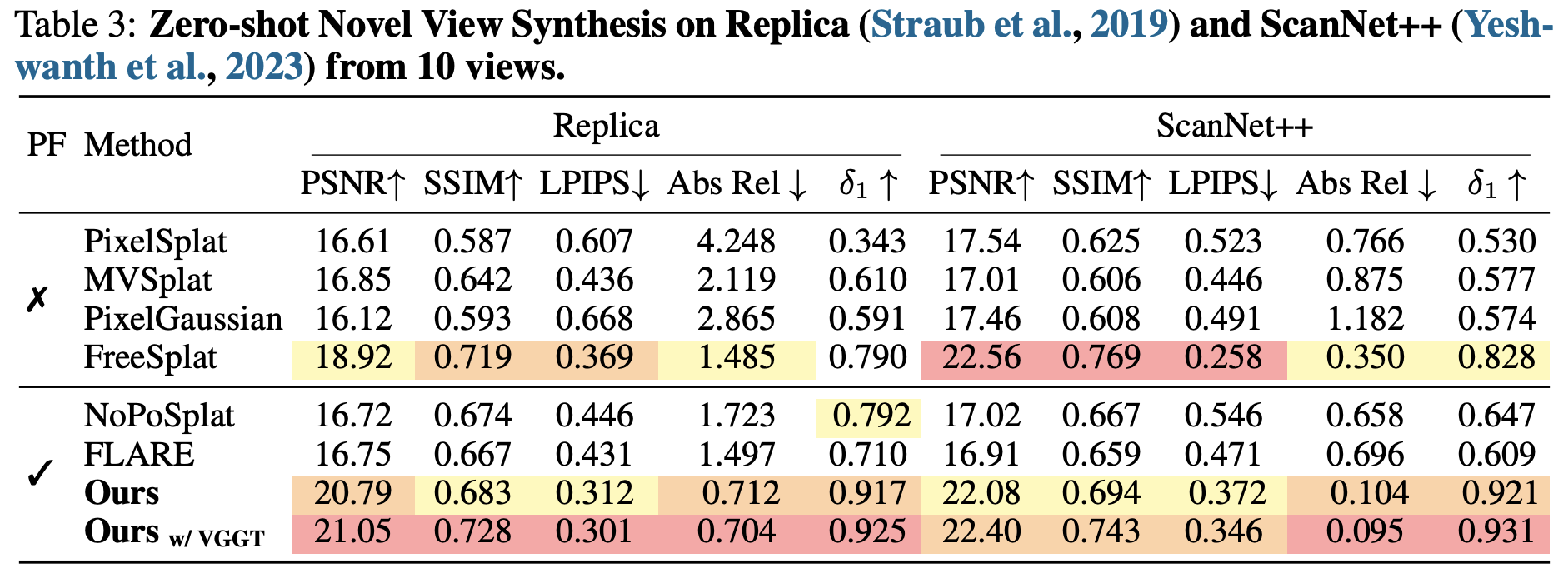
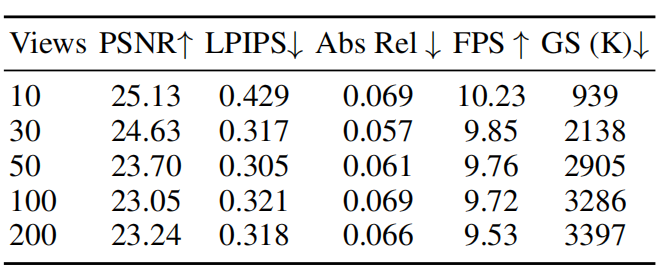
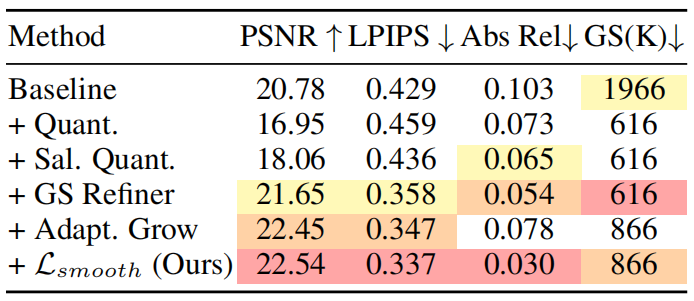
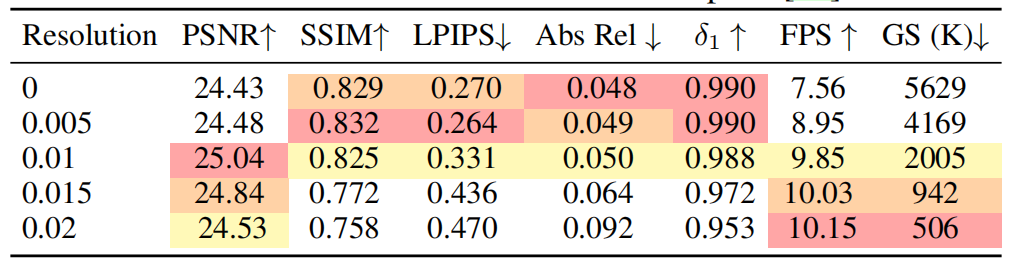
Abstract

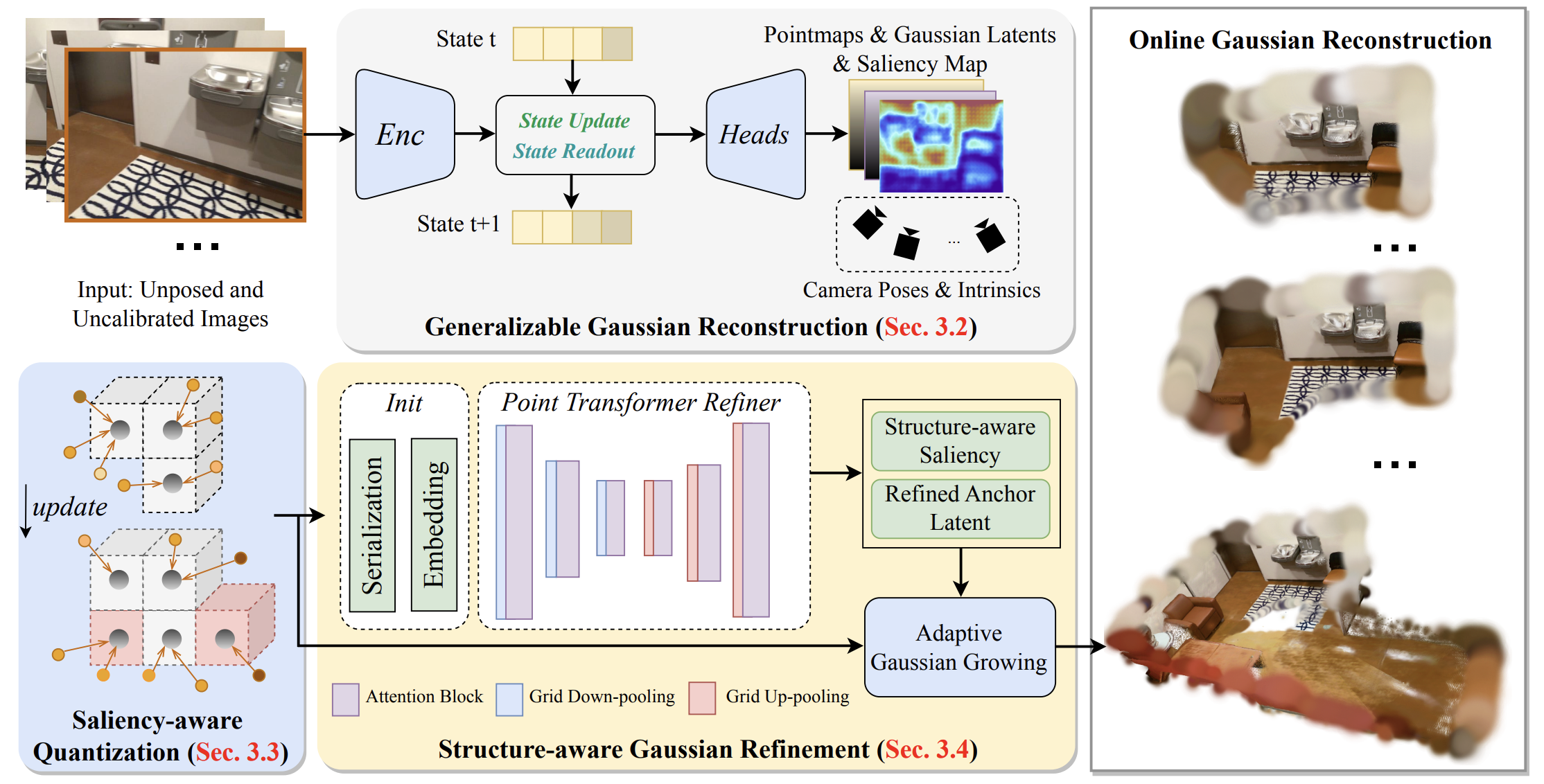
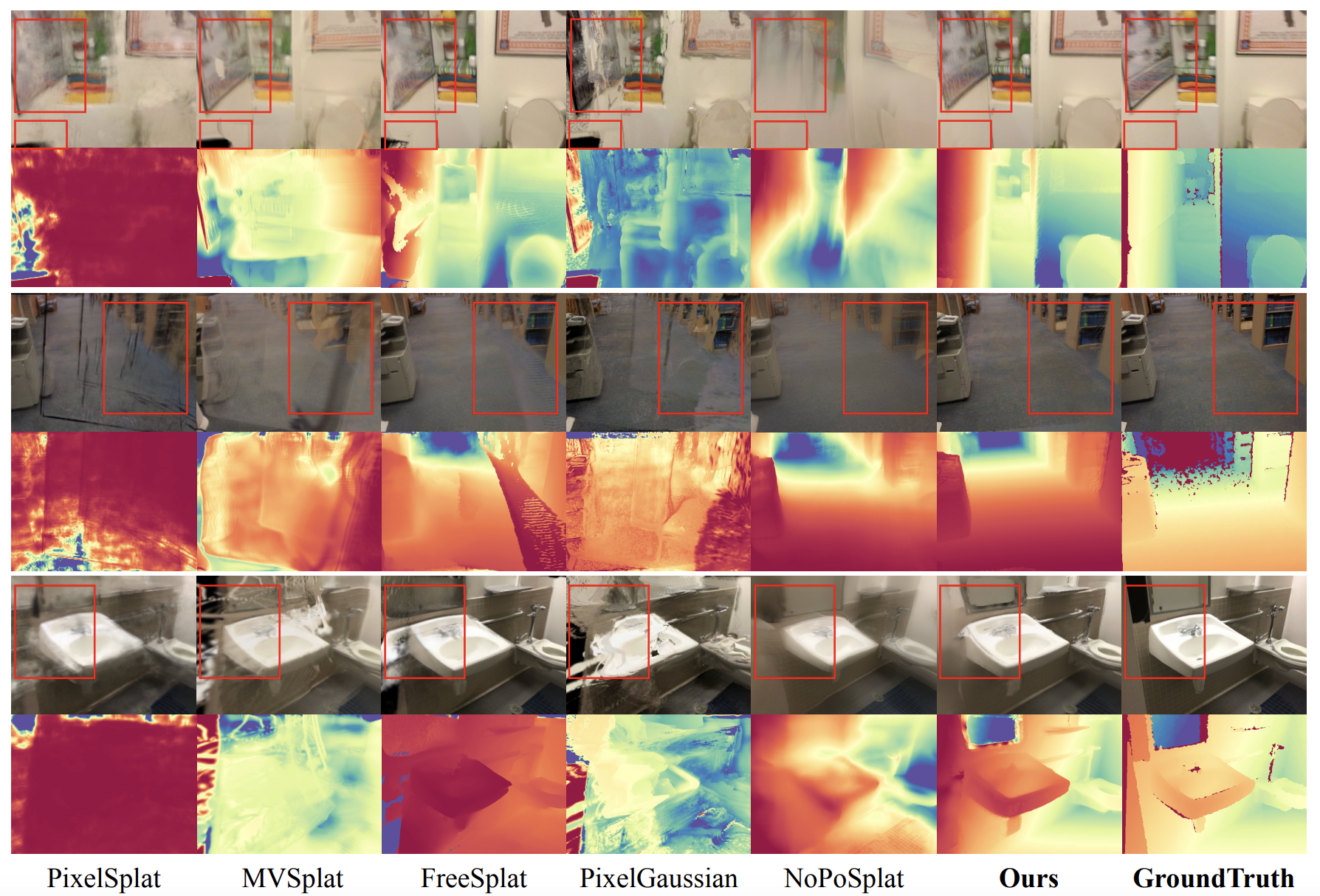
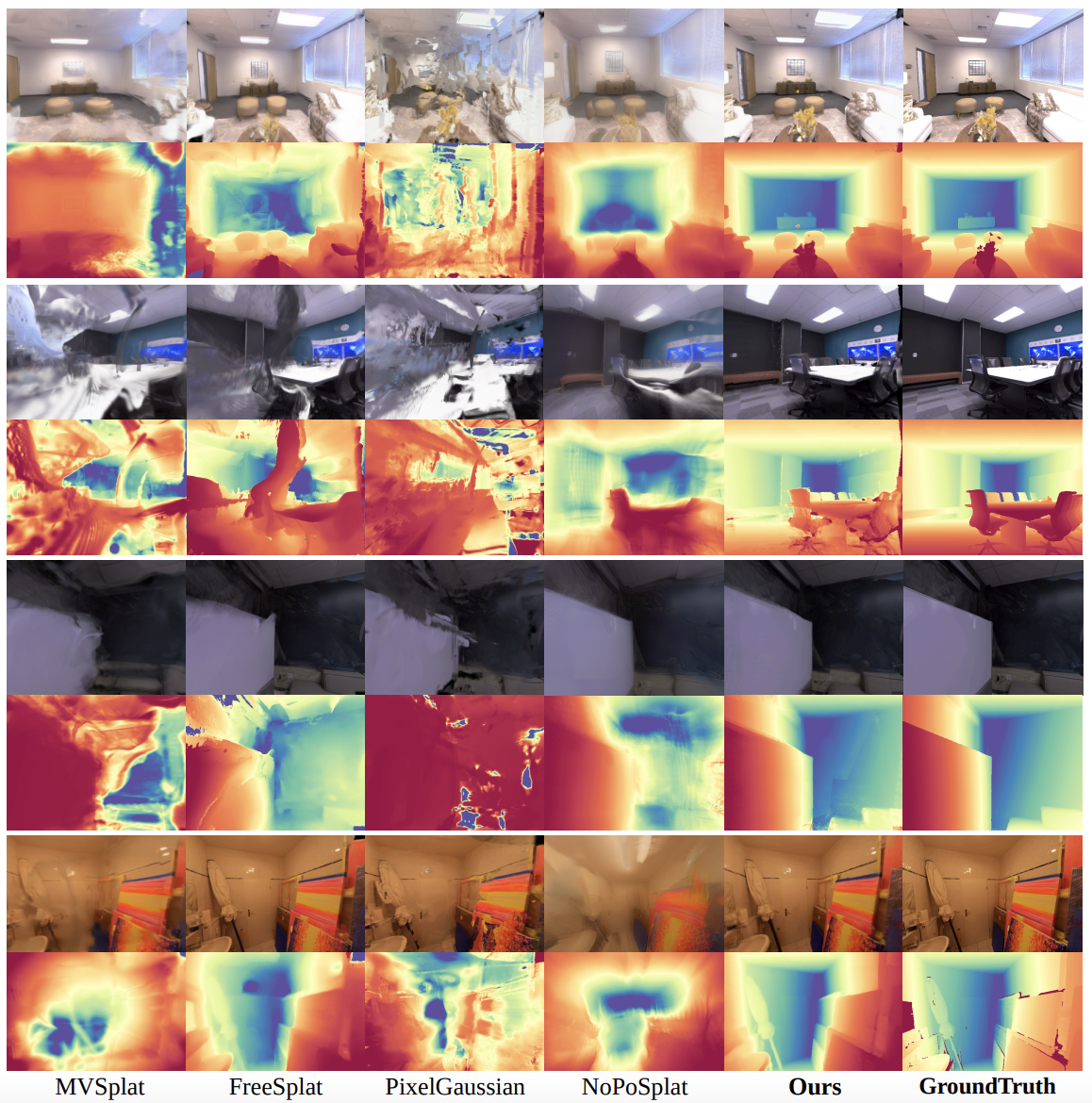
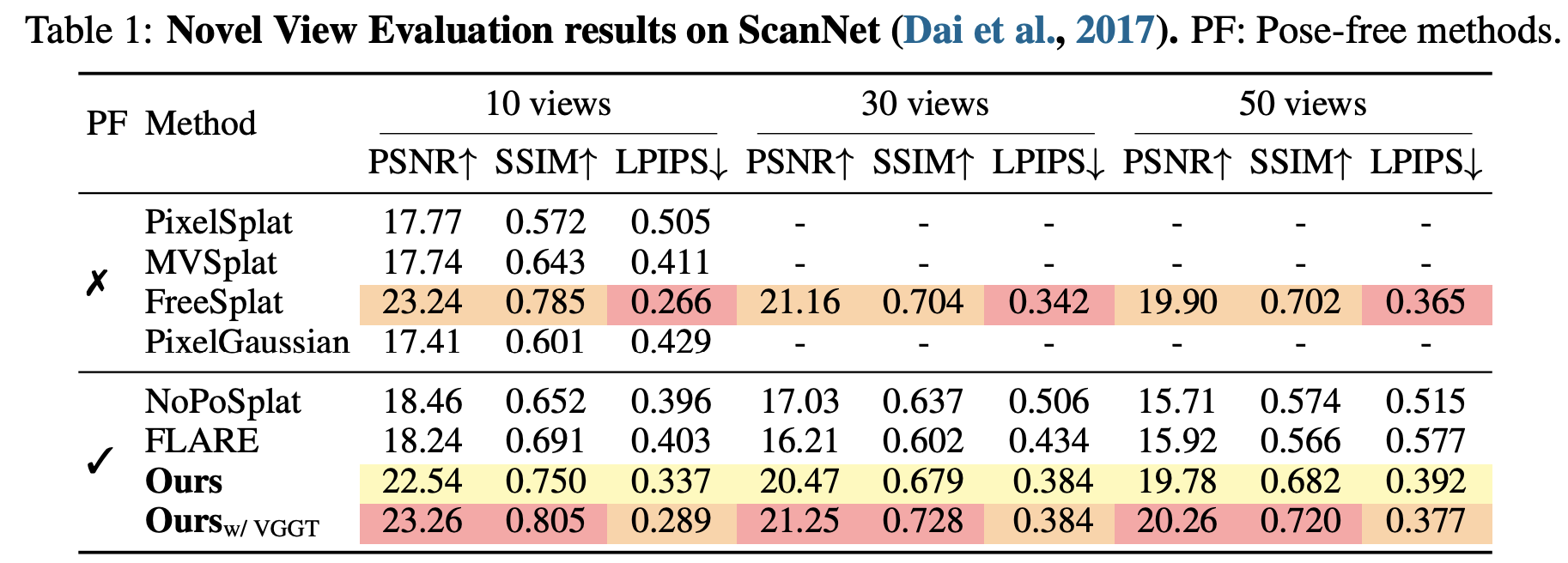
Recent advances in 3D Gaussian Splatting (3DGS) have enabled generalizable, on-the-fly reconstruction of sequential input views. However, existing methods often predict per-pixel Gaussians and combine Gaussians from all views as the scene representation, leading to substantial redundancies and geometric inconsistencies in long-duration video sequences. To address this, we propose SaLon3R, a novel framework for Structure-aware, Long-term 3DGS Reconstruction. To our best knowledge, SaLon3R is the first online generalizable GS method capable of reconstructing over 50 views in over 10 FPS, with 50% to 90% redundancy removal. Our method introduces compact anchor primitives to eliminate redundancy through differentiable saliency-aware Gaussian quantization, coupled with a 3D Point Transformer that refines anchor attributes and saliency to resolve cross-frame geometric and photometric inconsistencies. Specifically, we first leverage a 3D reconstruction backbone to predict dense per-pixel Gaussians and a saliency map encoding regional geometric complexity. Redundant Gaussians are compressed into compact anchors by prioritizing high-complexity regions. The 3D Point Transformer then learns spatial structural priors in 3D space from training data to refine anchor attributes and saliency, enabling regionally adaptive Gaussian decoding for geometric fidelity. Without known camera parameters or test-time optimization, our approach effectively resolves artifacts and prunes the redundant 3DGS in a single feed-forward pass. Experiments on multiple datasets demonstrate our state-of-the-art performance on both novel view synthesis and depth estimation, demonstrating superior efficiency, robustness, and generalization ability for long-term generalizable 3D reconstruction. Code will be released.